![Thợ Sửa Máy Giặt [ Tìm Thợ Sửa Máy Giặt Ở Đây ]](https://thomaygiat.com/wp-content/uploads/sua-may-giat-lg-tai-nha-1.jpg)
[MỚI NHẤT] Crawl data là gì? Hướng dẫn Crawl data từ A-Z
Mục Chính
Tổng quan về Crawl data
Crawl data là quy trình thu thập dữ liệu và thông tin website nhằm mục đích Giao hàng nhiều tiềm năng khác nhau. Theo đó, những bot của công cụ tìm kiếm ( Search Engine ) như Google, Bing, … sẽ lần lượt truy vấn vào toàn bộ trang trên website cũng như link tương quan để thống kê dữ liệu .
Dữ liệu thu về trong từng lần Crawl data sẽ gửi tới sever tìm kiếm kèm theo thời hạn hoàn tất Crawl trước đó để tổng hợp, nghiên cứu và phân tích trước khi đưa ra quyết định hành động Index. Dành cho những ai chưa biết, Index ( lập chỉ mục ) là quy trình thêm, đúng mực hơn là xếp hạng thứ bậc tìm kiếm của website theo từng nội dung tìm kiếm .
Quay trở lại với Crawl dữ liệu, đây là một quá trình quan trọng đối với Search Engine cũng như SEO, bởi quá trình này mang đến những đánh giá đúng nhất về chất lượng của website. Qua đó, thứ hạng tìm kiếm được tối ưu và quyết định chính xác hơn.
Bạn đang đọc: [MỚI NHẤT] Crawl data là gì? Hướng dẫn Crawl data từ A-Z
Crawl data là gì ?
Để triển khai việc làm này, Search Engine cần đến những công cụ tương hỗ đặc trưng, được gọi chung là Web Crawler. Đối với Google, Web Crawler của họ mang tên Googlebot hay Spider, được cho phép mày mò, tích lũy thông tin của toàn bộ những trang công khai minh bạch trên mạng World Wide Web ( WWW ). Cụ thể, quy trình “ Crawl data from website ” của Google được thực thi như sau :
- Người dùng submit một website / sơ đồ website ( sitemap ) trên công cụ Google Search Console hoặc từ list những website từ lần thu thập dữ liệu trước .
- Công cụ Spider triển khai tích lũy thông tin trên website / sơ đồ website ( sitemap ) đã được submit .
Nếu có link trên website / sơ đồ website ( sitemap ) này, Web Crawler của Google sẽ dò theo và thống kê tổng thể dữ liệu tương ứng. Như vậy, từ một trang hay website đã submit khởi đầu, lượng website được tổng hợp hoàn toàn có thể lên đến hàng chục, thậm chí còn là hàng trăm, tùy thuộc vào mạng lưới hệ thống link .
Đặc biệt, những Web Crawler rất “ nhạy cảm ” với website mới hoặc những biến hóa của website có độ uy tín cao. Bên cạnh đó, những link không còn hoạt động giải trí cũng được những công cụ này quản trị chặt. Vì chúng có tác động ảnh hưởng trực tiếp tới chất lượng của website tương quan .
Hiện nay, Crawl dữ liệu là thường được những công cụ tìm kiếm triển khai một cách tự động hóa và có tính độc lập cao. Nghĩa là, khó có người dùng hay doanh nghiệp nào can thiệp được vào hoạt động giải trí thu thập dữ liệu của Google, Bing, …
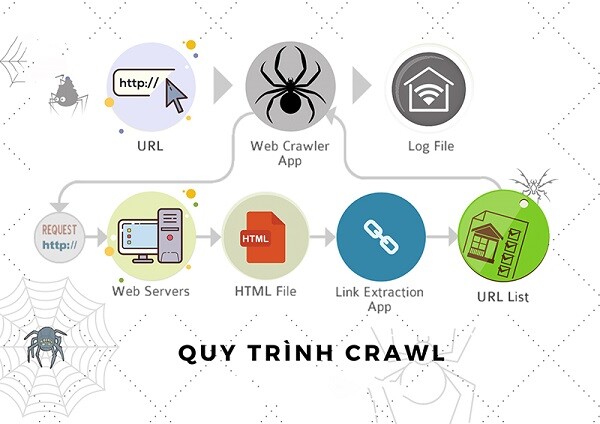
Quy trình Crawl data
Tuy nhiên, xuất phát từ những giá trị tuyệt vời hoàn toàn có thể nhận, nhiều cá thể, tổ chức triển khai vẫn cố gắng nỗ lực thực thi bằng chiêu thức riêng như Crawl data Python, Crawl data JavaScript, … Câu hỏi đặt ra, những yếu tố nào hoàn toàn có thể tác động ảnh hưởng tới quy trình thu thập dữ liệu website kể trên ? Đó là :
Backlink:
Càng nhiều backlink chất lượng, độ tin cậy và uy tín của website càng cao. Nếu website có thứ hạng tốt nhưng hạn chế lượng backlink, công cụ tìm kiếm có thể đánh giá nội dung trên trang có chất lượng thấp.
Liên kết nội bộ của website:
Liên kết nội bộ có thể mang đến hiệu quả SEO và giá trị sử dụng tốt. Tuy nhiên, cần đảm bảo tính mạch lạc, thống nhất với một mật độ phù hợp.
Sitemap XML:
Sitemap XML vừa giúp tạo sơ đồ trang web tự động, vừa là tín hiệu cho Google biết website đã sẵn sàng để được Crawl dữ liệu.
Các nội dung bị trùng lặp trên website:
Mức độ trùng lặp càng lớn càng khiến trang web bị đánh giá thấp. Do đó, hãy cố gắng tạo nên tính độc đáo, mới lạ cho từng nội dung đăng tải.
- URL: URL cần có sự thân thiện với SEO.
Tag Meta của trang:
Tag Meta của trang cần độc nhất và không mang tính cạnh tranh.
Ping:
Hãy nhớ rằng, bạn cần thêm tất cả các site ping chính vào trang website WordPress.
Vai trò của Crawl data từ website
Đối với công cụ tìm kiếm
Bạn hoàn toàn có thể tưởng tượng, những Search Engine đang nỗ lực tạo ra một “ TT thương mại trên khoảng trống mạng ”. Trong đó, mỗi website là một quầy bán hàng, mỗi cá thể truy vấn web là một người tiêu dùng. Thành công của TT thương mại đặc biệt quan trọng này không chỉ đến từ số lượng những bên tham gia mà còn được quyết định hành động ở năng lực quản trị của Google, Bing, … Cụ thể, đó là việc tối ưu hóa khoảng trống, tương hỗ người dùng thuận tiện tiếp cận website tương thích với từ khóa được tìm kiếm hay vô hiệu những “ quầy bán hàng cấm ” .
Vai trò của Crawl data từ website so với công cụ tìm kiếm
Rõ ràng, để triển khai xong tiềm năng ấy, một trong những việc làm không hề thiếu là thu thập dữ liệu và nhìn nhận website trải qua Crawl dữ liệu. Ngược lại, nếu công cụ tìm kiếm không chứng tỏ được vai trò của mình trong yếu tố quản trị khoảng trống WWW, họ sẽ bị vượt mặt bởi đối thủ cạnh tranh cạnh tranh đối đầu và rơi vào quên béng. Trong lịch sử vẻ vang, tất cả chúng ta đã tận mắt chứng kiến điều tựa như xảy ra với Yahoo .Đối người dùng truy cập web nói chung
Khi Search Engine triển khai tốt quy trình Crawl data from website sẽ giúp người dùng thuận tiện tìm được những bài viết, website có nội dung tương thích với keyword của mình. Trong toàn cảnh hàng tỷ website đang sống sót trên WWW, nếu như không có sự tối ưu của Google, Bing, Edge, … rõ ràng bạn sẽ như lạc vào hoang mạc chứa đầy thông tin. Người dùng sẽ cần rất nhiều thời hạn, công sức của con người để tìm kiếm và lựa chọn dữ liệu chất lượng và tương thích nhất cho mình .
Đối với doanh nghiệp
Thông qua những chiêu thức thu thập dữ liệu đặc biệt quan trọng như : Crawl data Python hay JavaScript, … doanh nghiệp hoàn toàn có thể sử dụng chúng vào nhiều mục tiêu khác nhau trong Marketing gồm có :
- Nắm bắt được thông tin từ những đối thủ cạnh tranh cạnh tranh đối đầu .
- Tối ưu SEO từ việc tìm kiếm được những nội dung hay, mê hoặc .
- Tiết kiệm thời hạn, sức lực lao động và ngân sách trong những chiến dịch tiếp thị .
Điều chỉnh kế hoạch Marketing, xa hơn là chiến lược kinh doanh cho phù hợp,…
Vai trò của Crawl data với hoạt động giải trí Marketing của doanh nghiệp
Tóm lại, mỗi doanh nghiệp sẽ có những tiềm năng riêng khi tiến hành Crawl dữ liệu. Song, họ chỉ dừng lại ở việc thống kê một phần thông tin, dữ liệu của những website khác mà không hề tích lũy 100 % data hay trực tiếp đổi khác thứ hạng SEO .
Một chú ý quan tâm khác trong hướng dẫn Crawl data, đó là những công cụ tương hỗ từ bên thứ ba thường tiềm ẩn những rủi ro đáng tiếc nhất định. Bởi lẽ, mỗi khi website biến hóa cấu trúc html thì chương trình Crawl cần phải update để “ thích nghi ” .>> Xem thêm: ENTITY LÀ GÌ? CÁCH TẠO LẬP ENTITY BUILDING MỚI NHẤT (2022)
Hướng dẫn Crawl data dành cho người mới
Có nhiều giải pháp để cá thể, doanh nghiệp thực thi thu thập dữ liệu website. Dưới đây, bePOS xin san sẻ hướng dẫn Crawl data Python từ một trang báo để bạn tìm hiểu thêm những bước thực thi, đơn cử :
Bước 1: Cài đặt Module
- Lệnh thiết lập Requests :“pip install requests”.
- Lệnh setup Pillow :“pip install Pillow”.
Hướng dẫn Crawl data dành cho người mới
Bước 2: Thực hiện thu thập dữ liệu
Lấy dữ liệu từ trang web
Truy cập trình duyệt gõ codelearn.io và enter để nhận được giao diện website hoặc một dạng dữ liệu khác. Bạn sử dụng một module tương hỗ và Request để lấy được dữ liệu trả về .
- Lệnh 1 : “ requests.method ( url, params, data, json, headers, cookies, files, auth, timeout, allow_redirects, proxies, verify, stream, cert ) ”
- Lệnh 2 : “ import requests
response = requests.get ( “ https://tuoitre.vn/tin-moi-nhat.htm ” )
print ( response ) ”
Kết quả nhận về: “
”
- Lệnh gọi thuộc tính : “ print ( response.content ) ”
Sau khi thực thi, bạn sẽ nhận được hiệu quả trả về .
Thực hiện tách dữ liệu qua module beautifulSoup4
- Thực hiện thiết lập :“pip install beautifulsoup4.”
- Thực hiện lệnh :
“ import requests
from bs4 import BeautifulSoup
response = requests.get ( “ https://tuoitre.vn/tin-moi-nhat.htm ” )
soup = BeautifulSoup ( response.content, “ html.parser ” )
print ( soup ) ”
Như vậy bạn đã hoàn thành xong những bước để thu thập dữ liệu trên website .>> Xem thêm: BÍ QUYẾT SEO TỪ KHÓA LÊN TOP 1 GOOGLE HIỆU QUẢ NHẤT 2022
Trên đây là những san sẻ của bePOS về Crawl data. Hy vọng rằng, bài viết đã mang lại nhiều kiến thức và kỹ năng hữu dụng dành cho bạn. Đừng quên ghé qua blog của bePOS mỗi ngày để update thêm nhiều bài viết hơn nữa .
FAQ
Những yếu tố ảnh hưởng tới Crawl data from website là gì?
Có nhiều yếu tố ảnh hưởng tác động tới quy trình thu thập dữ liệu website, trong đó đa phần là : Backlink, link nội bộ, Sitemap XML, URL, …




Ngoài các bot của công cụ tìm kiếm, có những phương pháp Crawl dữ liệu phổ biến nào?
Bên cạnh những bot của công cụ tìm kiếm, một số ít chiêu thức thu thập dữ liệu phổ cập là Crawl data Python hay JavaScript, …
Source: https://thomaygiat.com
Category : Kỹ Thuật Số
![[MỚI NHẤT] Crawl data là gì? Hướng dẫn Crawl data từ A-Z](https://thomaygiat.com/wp-content/uploads/2-36-1.jpg)

Chuyển vùng quốc tế MobiFone và 4 điều cần biết – MobifoneGo
Muốn chuyển vùng quốc tế đối với thuê bao MobiFone thì có những cách nào? Đừng lo lắng, bài viết này của MobiFoneGo sẽ giúp…
Cách copy dữ liệu từ ổ cứng này sang ổ cứng khác
Bạn đang vướng mắc không biết làm thế nào để hoàn toàn có thể copy dữ liệu từ ổ cứng này sang ổ cứng khác…
Hướng dẫn xử lý dữ liệu từ máy chấm công bằng Excel
Hướng dẫn xử lý dữ liệu từ máy chấm công bằng Excel Xử lý dữ liệu từ máy chấm công là việc làm vô cùng…

Cách nhanh nhất để chuyển đổi từ Android sang iPhone 11 | https://thomaygiat.com
Bạn đã mua cho mình một chiếc iPhone 11 mới lạ vừa ra mắt, hoặc có thể bạn đã vung tiền và có một chiếc…
Giải pháp bảo mật thông tin trong các hệ cơ sở dữ liệu phổ biến hiện nay
Hiện nay, với sự phát triển mạnh mẽ của công nghệ 4.0 trong đó có internet và các thiết bị công nghệ số. Với các…
4 điều bạn cần lưu ý khi sao lưu dữ liệu trên máy tính
08/10/2020những chú ý khi tiến hành sao lưu dữ liệu trên máy tính trong bài viết dưới đây của máy tính An Phát để bạn…